 DE
DE  FR
FR RegOps-Whitepaper-Regnology-A-new-approach-towards-the-future-of-regulatory-reporting.pdf
Whitepaper: The Future of data collection and data management: Agile RegOps for digitalizing the regulatory value chain
Since the 2007-2008 financial crisis, global regulatory regimes and reporting have improved significantly, and the Basel reforms were broadly deemed sufficient. However, the widespread easing of regulatory requirements and additional ad hoc requests due to the COVID-19 crisis coupled with the high costs for financial institutions (FI) highlight that the current regulatory reporting model is not sustainable enough, especially in times of intense stress.
In most regulatory frameworks in global jurisdictions, regulatory data flow still happens in a quasi-manual, template-based fashion. This means that the mere automatization of manual, printed, or handwritten reporting processes of aggregated data, which was the main activity in the past years, is not enough.
To a large extent, the current high costs in regulatory data generation for institutions are rooted in the necessity to leverage the same information artefacts over and over again for different non-aligned regulatory reporting regimes with myriads of templates (prudential, national, statistical, granular, resolution reporting) with often very similar, but slightly differing definitions.
For one, offsite supervisory overview is still limited due to the nature of the collected data. Aggregated and template-based reporting is conceptually more prone to data correction or even manipulation. Another problem is the lack of quality, timeliness, and inter-entity matching, meaning the complementary fit of the two datasets, representing two sides of the same transaction.
To overcome these issues, we have proposed a new approach, called RegOps, to systematically change how regulation is developed and deployed and how data is exchanged between regulators and regulated using push and pull approaches.
RegOps is closely connected to the term DevOps, known from software development and seen as the answer to the shortcomings of the waterfall model. Regulation has been developed (conceptualized, drafted, released) and rolled out according to the waterfall model over the decades, leading to disastrous, purely reactive time-to-market and offering hardly any flexibility in embracing regulatory change. Most of all, it created enormous costs to regulators but, more importantly, to the financial services industry. Similar to DevOps, RegOps improves the way regulators and regulated entities interact: collaboration, continuous delivery, constant feedback and communication between regulators and the regulated, while delivering regulatory change incrementally in small releases without affecting the whole system.
When we combine these elements, we can see a system facilitating direct, fully integrated access of regulators to the contract-granular regulatory databases of the financial institutions via APIs from various data sources (e.g. legacy data warehouses, data lakes, distributed ledger / blockchain systems). The collected data is then validated, refined and transformed for analysis, via standardized regulatory processing & allocation logic. The mined granular data can then be flexibly accessed & visualized via BI tools in the form of existing templates and more interesting formats and is a solid foundation for the application of advanced analytics or AI approaches.
RegOps – A new approach towards the future of regulatory reporting
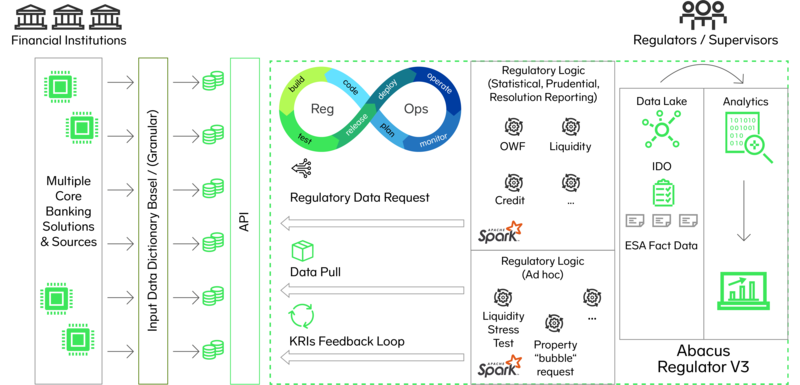
This approach helps to streamline the reporting stream as far as possible and largely solves the issues of system breaks in the current regulatory reporting flow. Furthermore, it helps to solve the issues of standardization for the data model and the data processing logic to ensure the highest possible quality and comparability.
Interested to learn more? Read the whitepaper "The Future of data collection and data management: Agile RegOps for digitalizing the regulatory vaule chain by Martina Drvar (Croatian National Bank) Dr. Johannes Turner, (Österreichische Nationalbank), Maciej Piechocki (Regnology), Eric Stiegeler (Regnology) and Daniel Münch (Regnology) and contact us for more information.

Chief Revenue Officer
Maciej Piechocki, as the Chief Revenue Officer, is responsible for Sales, Sales Operations and Account Management, and is driving the international market development for Regnology’s solutions. He has been specializing in the areas of technology and regulation, particularly in the financial services sector, and has been working with banks, insurance companies, central banks, and federal authorities across the globe.

Whitepaper: The Future of data collection and data management: Agile RegOps for digitalizing the regulatory value chain
Insight
Get expert insights and market practices to streamline your sustainability reporting.
Read moreInsight
This is the third and final article in a series of Chartis Points of View that explore the evolution of regulatory reporting technology and the context in which it is changing.
Read moreInsight
The second chapter in a series of Point of View white papers exploring the evolution of regulatory reporting technology and the context in which it is transforming.
Read more© 2025 Regnology Group GmbH All Rights Reserved


