 EN
EN  FR
FR 

RegOps-Whitepaper-Regnology-A-new-approach-towards-the-future-of-regulatory-reporting.pdf
Whitepaper: "The Future of data collection and data management: Agile RegOps for digitalizing the regulatory value chain" (auf Englisch)
Seit der Finanzkrise 2007-2008 haben sich die globale Bankenregulierung und das Meldewesen deutlich verbessert, und die Baseler Reformen gelten im Großen und Ganzen als erfolgreich. Die Lockerung regulatorischer Anforderungen und zusätzliche Ad hoc-Anfragen aufgrund der COVID-19 Krise in Verbindung mit den hohen Kosten für Finanzinstitute (FI) machen jedoch deutlich, dass das derzeitige aufsichtsrechtliche Meldewesen operativ schwer zu handhaben ist, insbesondere in Krisensituationen.
In den meisten regulatorischen Rahmenwerken in Jurisdiktionen erfolgt weltweit der regulatorische Datenfluss immer noch auf quasi-manuelle, Template-basierte Weise. Diese reine Automatisierung von manuellen, gedruckten oder handschriftlichen Meldeprozessen von aggregierten Daten, das in den vergangenen Jahren die übliche Vorgehensweise war, ist aber nicht ausreichend.
Die derzeit hohen Kosten der Bereitstellung regulatorischer Daten durch die Institute sind zu einem großen Teil auf die Tatsache zurückzuführen, dass identische Vertragsinformationen immer wieder in einer Vielzahl verschiedener, nicht angeglichener Templates (aufsichtsrechtliche, nationale, statistische, granulare, Abwicklungsmeldungen) mit oft sehr ähnlichen, aber leicht abweichenden Definitionen aufbereitet werden müssen.
Die Qualität der Finanzmarktüberwachung ist aufgrund der Beschaffenheit der erhobenen Daten nach wie vor eingeschränkt. Aggregierte und Template-basierte Meldungen benötigen konzeptionell oft Datenkorrekturen oder sind anfällig für Manipulation. Ein weiteres Problem ist die fehlende Qualität, Aktualität und das fehlende Inter-Entity-Matching, also die komplementäre Übereinstimmung der Datensätze zweier Vertragsparteien zu einer Transaktion.
Um diese Probleme zu überwinden, haben wir den neuen Ansatz „RegOps“, entwickelt, um systematisch zu ändern, wie Regulierung entworfen, bereitgestellt und eingesetzt wird und wie regulatorische Daten zwischen Regulatoren und Regulierten unter Verwendung von Push- und Pull-Ansätzen ausgetauscht werden.
RegOps ist eng mit dem Begriff DevOps verbunden, der aus der Softwareentwicklung bekannt ist und als Antwort auf die Unzulänglichkeiten des Wasserfallmodells gesehen wird. Regulierungen wurden über Jahrzehnte hinweg nach dem Wasserfallmodell entwickelt (konzipiert, entworfen, freigegeben) und ausgerollt, was zu sehr langen Produkteinführungszeiten (Time-to-Market) führte und kaum Flexibilität bei regulatorischen Änderungen bot. Dieser Ansatz verursacht für die Aufsichtsbehörden, aber vor allem auch für die Finanzdienstleistungsbranche sehr hohe Kosten. Ähnlich wie DevOps verbessert RegOps die Art und Weise, wie Aufsichtsbehörden und regulierte Unternehmen interagieren: Zusammenarbeit, kontinuierliche Bereitstellung, ständiges Feedback und Kommunikation zwischen Aufsichtsbehörden und Regulierten, bei gleichzeitiger inkrementeller Bereitstellung von regulatorischen Änderungen in kleinen Releases, ohne das gesamte System negativ zu beeinflussen.
Kombinieren wir diese Elemente, bildet sich ein System, das den direkten, voll integrierten Zugriff der Aufsichtsbehörden auf die vertragsgranularen regulatorischen Datenbanken der Finanzinstitute über APIs (Application Programming Interface) aus verschiedenen Datenquellen (z. B. Legacy Data Warehouses, Data Lakes, Distributed Ledger/Blockchain-Systeme) ermöglicht. Die gesammelten Daten werden dann validiert, aufbereitet und für die Analyse transformiert, und zwar über eine standardisierte Verarbeitungs- und Allokationslogik. Die gewonnenen granularen Daten können dann über BI-Programme (Business Intelligence) in Form von bestehenden Templates und interessanteren Formaten flexibel abgerufen & visualisiert werden und bilden eine solide Grundlage für die Anwendung von erweiterten Analysen (Advanced Analytics) oder KI-Ansätzen (Künstliche Intelligenz).
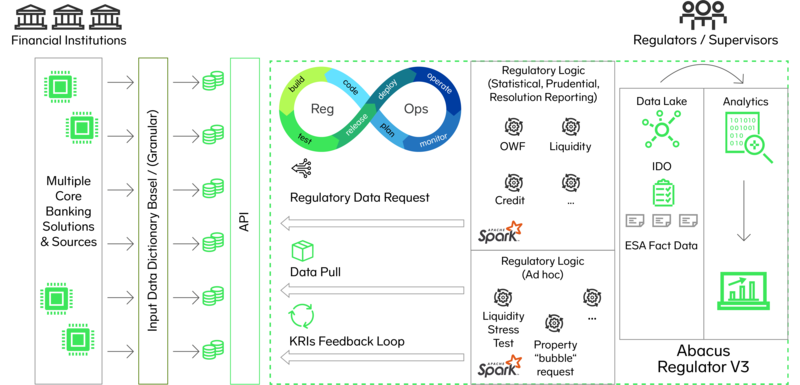
Dieser Ansatz trägt dazu bei, den Meldewesen-Datenfluss so weit wie möglich zu straffen und löst weitgehend die derzeitigen Probleme von Systembrüchen im aktuellen System. Darüber hinaus hilft es, die Probleme der Standardisierung für das Datenmodell und die Datenverarbeitungslogik zu lösen, um eine höchstmögliche Qualität und Vergleichbarkeit zu gewährleisten.
Möchten Sie mehr erfahren? Lesen Sie das Whitepaper "The Future of data collection and data management: Agile RegOps zur Digitalisierung der regulatorischen Wertschöpfungskette" von Martina Drvar (Kroatische Nationalbank) Dr. Johannes Turner, (Österreichische Nationalbank), Maciej Piechocki (Regnology), Eric Stiegeler (Regnology) und Daniel Münch (Regnology) und kontaktieren Sie uns für weitere Informationen.
Whitepaper: "The Future of data collection and data management: Agile RegOps for digitalizing the regulatory value chain" (auf Englisch)
© 2026 Regnology Group GmbH All Rights Reserved